
Файл robots.txt представляет собой набор директив (набор правил для роботов), с помощью которых можно запретить или разрешить поисковым роботам индексирование определенных разделов и файлов вашего сайта, а также сообщить дополнительные сведения. Изначально с помощью robots.txt реально было только запретить индексирование разделов, возможность разрешать к индексации появилась позднее, и была введена лидерами поиска Яндекс и Google.
Структура файла robots.txt
Сначала прописывается директива User-agent, которая показывает, к какому поисковому роботу относятся инструкции.
Небольшой список известных и частоиспользуемых User-agent:
User-agent:*
User-agent: Yandex
User-agent: Googlebot
User-agent: Bingbot
User-agent: YandexImages
User-agent: Mail.RU
Далее указываются директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. Затем повторяем данные действия для следующего User-agent. В конце файла указывается директива Sitemap, где задается адрес карты вашего сайта.
Прописывая директивы Disallow и Allow, можно использовать специальные символы * и $. Здесь * означает «любой символ», а $ – «конец строки». Например, Disallow: /admin/*.php означает, что запрещается индексация индексацию всех файлов, которые находятся в папке admin и заканчиваются на .php, Disallow: /admin$ запрещает адрес /admin, но не запрещает /admin.php, или /admin/new/ , если таковой имеется.
Если для всех User-agent использует одинаковый набор директив, не нужно дублировать эту информацию для каждого из них, достаточно будет User-agent: *. В случае, когда необходимо дополнить информацию для какого-то из user-agent, следует продублировать информацию и добавить новую.
Пример robots.txt для WordPress:
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ru
Примечание для User agent: Yandex
— Для того чтобы передать роботу Яндекса Url без Get параметров (например: ?id=, ?PAGEN_1=) и utm-меток (например: &utm_source=, &utm_campaign=), необходимо использовать директиву Clean-param

— Ранее роботу Яндекса можно было сообщить адрес главного зеркала сайта с помощью директивы Host. Но от этого метода отказались весной 2018 года.
— Также ранее можно было сообщить роботу Яндекса, как часто обращаться к сайту с помощью директивы Crawl-delay. Но как сообщается в блоге для вебмастеров Яндекса:
— Проанализировав письма за последние два года в нашу поддержку по вопросам индексирования, мы выяснили, что одной из основных причин медленного скачивания документов является неправильно настроенная директива Crawl-delay.
— Для того чтобы владельцам сайтов не пришлось больше об этом беспокоиться и чтобы все действительно нужные страницы сайтов появлялись и обновлялись в поиске быстро, мы решили отказаться от учёта директивы Crawl-delay.
Вместо этой директивы в Яндекс. Вебмастер добавили новый раздел «Скорость обхода».
Проверка robots.txt
Старая версия Search console
Для проверки правильности составления robots.txt можно воспользоваться Вебмастером от Google – необходимо перейти в раздел «Сканирование» и далее «Просмотреть как Googlebot», затем нажать кнопку «Получить и отобразить». В результате сканирования будут представлены два скриншота сайта, где изображено, как сайт видят пользователи и как поисковые роботы. А ниже будет представлен список файлов, запрет к индексации которых мешает корректному считыванию вашего сайта поисковыми роботами (их необходимо будет разрешить к индексации для робота Google).
Обычно это могут быть различные файлы стилей (css), JavaScript, а также изображения. После того, как вы разрешите данные файлы к индексации, оба скриншота в Вебмастере должны быть идентичными. Исключениями являются файлы, которые расположены удаленно, например, скрипт Яндекс.Метрики, кнопки социальных сетей и т.д. Их у вас не получится запретить/разрешить к индексации.
Новая версия Search console
В новой версии нет отдельного пункта меню для проверки robots.txt. Теперь достаточно просто вставить адрес нужной страны в строку поиска.
В следующем окне нажимаем «Изучить просканированную страницу».
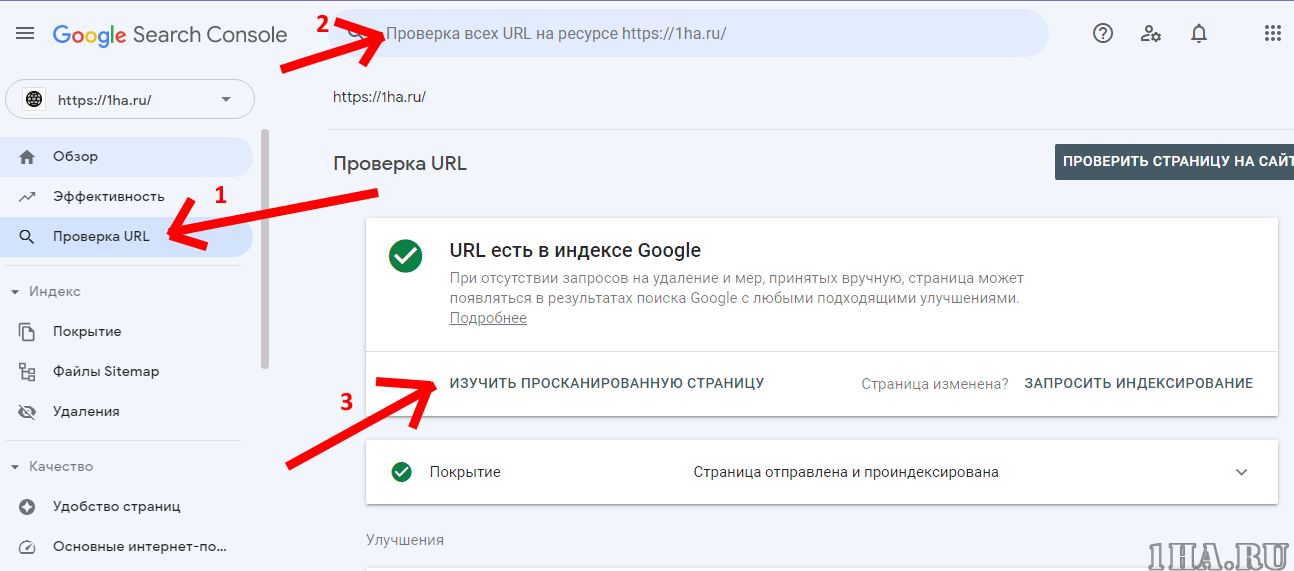
Далее нажимаем ресурсы страницы
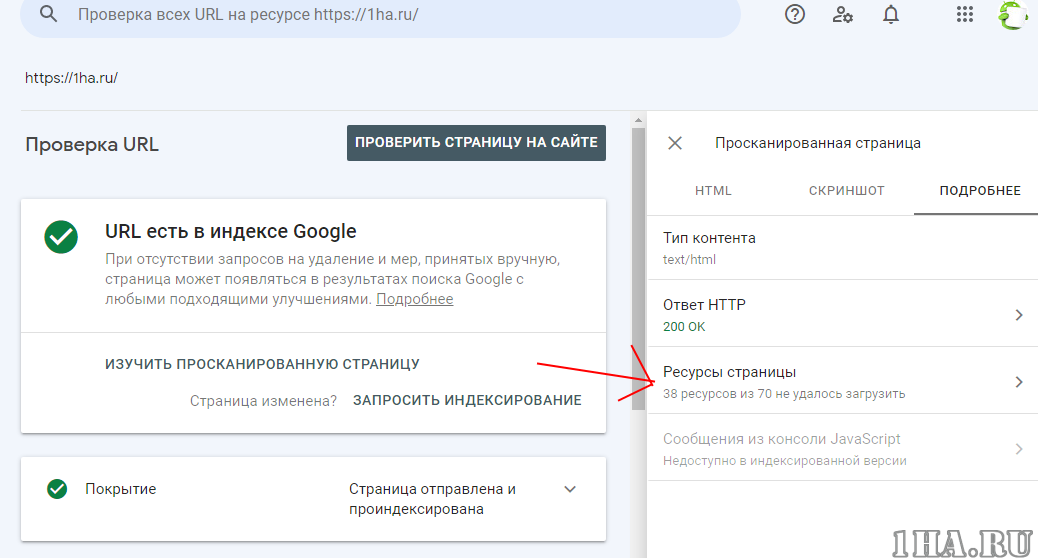
В появившемся окне видно ресурсы, которые по тем или иным причинам недоступны роботу google. В конкретном примере нет ресурсов, заблокированных файлом robots.txt.

Если же такие ресурсы будут, вы увидите сообщения следующего вида:
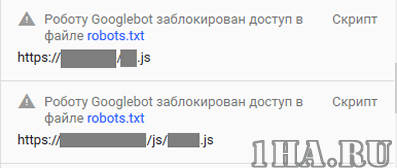
Рекомендации, что закрыть в robots.txt
Каждый сайт имеет уникальный robots.txt, но некоторые общие черты можно выделить в такой список:
— Закрывать от индексации страницы авторизации, регистрации, вспомнить пароль и другие технические страницы.
— Админ панель ресурса.
— Страницы сортировок, страницы вида отображения информации на сайте.
— Для интернет-магазинов страницы корзины, избранное. Более подробно вы можете почитать в советах интернет-магазинам по настройкам индексирования в блоге Яндекса.
— Страница поиска.
Это лишь примерный список того, что можно закрыть от индексации от роботов поисковых систем. В каждом случае нужно разбираться в индивидуальном порядке, в некоторых ситуациях могут быть исключения из правил.
Заключение
Файл robots.txt является важным инструментом регулирования отношений между сайтом и роботом поисковых систем, важно уделять время его настройке.
В статье большое количество информации посвящено роботам Яндекса и Google, но это не означает, что нужно составлять файл только для них. Есть и другие роботы – Bing, Mail.ru, и др. Можно дополнить robots.txt инструкциями для них.
Многие современные cms создают файл robots.txt автоматически, и в них могут присутствовать устаревшие директивы. Поэтому рекомендую после прочтения этой статьи проверить файл robots.txt на своем сайте, а если они там присутствуют, желательно их удалить.
